
【articles】 The memcpy optimization in LOonux -- 17 December 2013
Source: dev.lemote.com
The Alignment upgrading
Given two addresses dst and src, the implementation of memcpy can utilize wide moving instructions if dst and src are both N aligned.
E.g. in Loongson 3A processor, there has instructions that can load/store 16B data to/from two 64-bit registers. It will run its best performance if dst and src both are 16B aligned in an optimal memcpy implementation. However, this may not be the case in practice.
Let assume dst=0x5f0004,src=0x5f0c14, both are 4B aligned, which is not the case for 16B load/store instructions. However, if 12B copied first, dst and src will move forward to 0x5f0010 and 0x5f0c20, both are 16B aligned now.
The key is the difference of dst and src - if the difference can be divisible by the N, then dst and src can be upgraded to N-aligned case. In binary form, N-aligned means the number of trailing zeros, which can be counted by instructions like bsr.
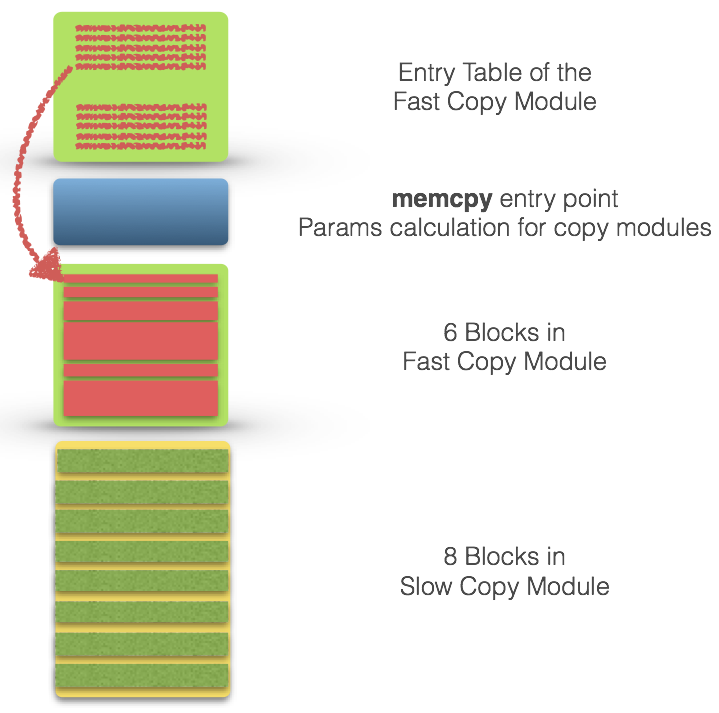
The workflow of our memcpy

The code layout of our memcpy.S
blog comments powered by Disqus